
今天,由中共沈阳市委组织部、中共皇姑区委员会、皇姑区人民政府和人民网共同主办的2023年东北亚(沈阳)人才交流大会“新一代信息技术”分论坛于沈阳圆满落幕。论坛以“聚焦新质生产力 释放发展新动能”为主题,汇集众多行业专家学社和技术领袖,讨论新一代信息技术的突破之道。

数势科技是行业领先的数据智能平台与技术服务企业,AI负责人李飞博士受邀出席论坛对话环节,并发表主旨演讲,探索AIGC在企业数字化发展中的核心应用,为东北亚地区数字化建设提供新思路。

落地基于大模型的产品开发是新一代信息技术的突破之道
“经过几十年的积累,人工智能技术迎来了爆发,它对于企业信息化建设和经营效率的提升有明显作用,而大模型是人工智能落地模式的变革,它将成为AI未来的操作系统,加速与硬件的适配,未来所有AI的算法开发和产品设计都将会围绕它来构建,”李飞博士在对话中表明,“大模型是AI技术发展到一定阶段后的新机会,怎么把这么大模型技术变成用户体验很好的产品,这一步是最能产生影响力的,也是突破信息技术建设发展瓶颈的关键。”
当前大模型发展层次 最下面是算力层,它是构建一切模型和应用的基础。为了满足下游不同形式开发所需要的算力,许多芯片厂商正在围绕芯片的广度和深度进行攻坚。广度主要关注如何扩大产能,深度则专注如何实现性能的突破。
最下面是算力层,它是构建一切模型和应用的基础。为了满足下游不同形式开发所需要的算力,许多芯片厂商正在围绕芯片的广度和深度进行攻坚。广度主要关注如何扩大产能,深度则专注如何实现性能的突破。
其次是基础模型层,包括GPT系列、文心一言等闭源大模型,也包括Baichuan、ChatGLM等开源大模型。随着基础大模型生态的快速发展,这给企业增加了更多的选择。
有了这么多的基础大模型后,企业如何基于不同的大模型快速简单的构建下游应用、甚至微调一些模型?大模型的托管平台和中间件平台应运而生,它们通过管理大模型,封装一些构建过程中的组件帮助开发者提高开发效率。
最后就是企业要基于大模型构建什么样的产品应用。例如,针对不同行业的数据,对基础大模型进行微调,构建行业专属大模型,或者基于大模型和向量库的方法衍生开发AI原生应用 AI Agent和RAG知识库等。
按照上述层级划分,不同层级的落地难度和成本也各不相同。基础大模型构建难度和成本较高,投入成本多达数十亿甚至上百亿,训练一次的时间以月为计算单位。层级向上成本依次递减,如提示语工程建设成本和难度都相对最低,在chatGPT引爆市场以后,大量做提示语工程的用户和公司出现。目前,无论是通过撰写提示语激发模型潜力,还是基于回答结果去反向优化提示语,都取得了一定成果。
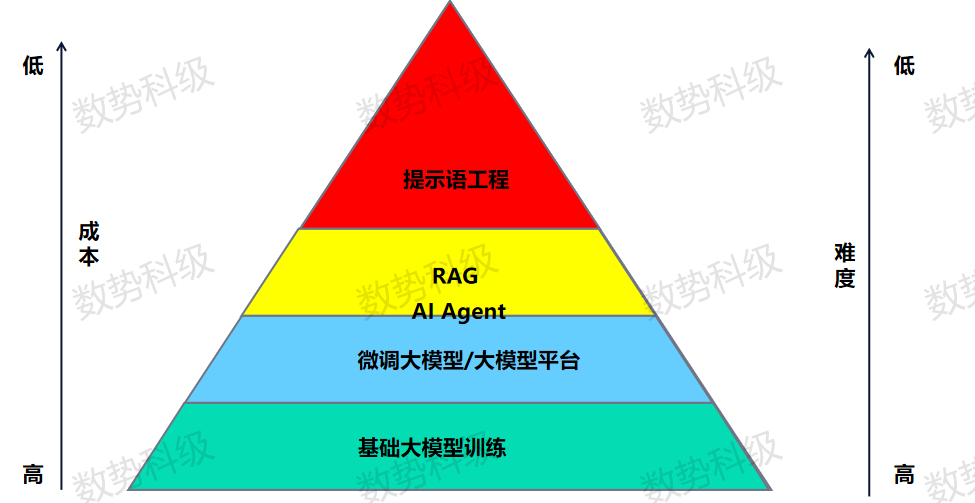
知识库问答构建和AI Agent是当前企业构建可落地大模型应用的重要方向
综合当前阶段企业数字化需求和大模型应用落地成本考虑,李飞博士认为RAG知识库问答构建和AI Agent赋能业务流程是当前企业构建可落地大模型应用的重要方向。
在大模型的思维模式中,基于上下文推理(Context Learning)是大模型的重要能力,然而它只适合有限的信息量,超过一定字符数量,训练语料便无法再次输入大模型进行学习储备,大模型得不到最新语料,便无法回答实时信息,因此,扩大模型的上下文是一个挑战;同时,目前现有LLM模型都是通用模型,输出结果不一定切合实际业务场景,如何将LLM模型落地到特定业务场景中,使得输出结果能输出预期的答案也是另一需要解决的重要问题。
李飞博士提出,RAG知识库问答构建是企业应重点关注的数字化建设方向,它是解决大模型“一本正经胡说八道”的重要解决方式,也是扩充大模型的边界,帮助企业快速获取内部知识并辅助业务决策的一种重要手段。
数势企业知识库产品功能架构如下图,底层包括一些向量的存储,历史会话信息的存储等,中间要适配不同的模型以及模型参数的选择(例如temperature等),功能界面包括prompt的指令管理,角色管理等,可向上应用于问答、营销文案撰写和特征总结等核心业务场景。
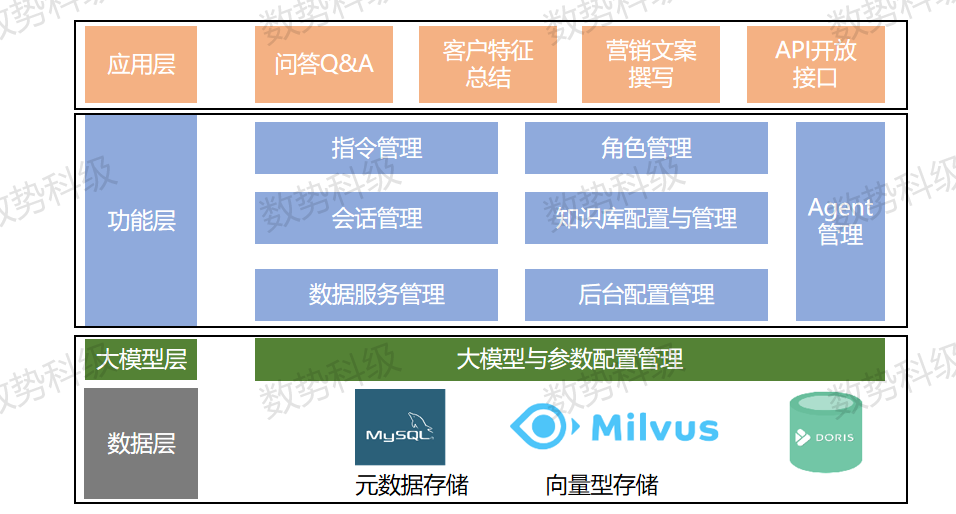
在技术构成方面,RAG主要包括数据提取和处理、embedding(向量化)、检索和LLM归纳生成等。其中,数据提取主要是针对不同格式的文件(PDF、word等)进行提取处理,并针对文件名、时间、作者title进行存储。数据提取后对数据进行切割技术团队需要考虑到模型的类型,因为不同类型的模型token限制长度不一样,会影响到切割的尺寸。同时还应考虑问答的文本长度,只有和问答的文本长度保持一致,才能提高检索的效率。embedding的模型选择也很重要,例如BGE、文心一言的embedding模型等表现都很强劲。检索就是如何基于上一步生成的embedding召回更相关的数据片段。
在RAG构建方法上,李飞博士也介绍了相关技巧,例如HYDE,即通过模型回答一些假答案,通过假答案和用户query的拼接召回文档片段。还有“重新召回”,即通过向量库的欧式距离召回20个片段,再通过cosine相似度重新判断10个最相似的片段进行下一步的拼接等。
同样地,归纳生成也有技巧,除了之前斯坦福大学提出的基于召回数据片段进行排序,例如相似度高的片段放到两侧,相似度低的偏度放到中间,最终和query拼接到一起让LLM进行归纳总结,RAG还可将归纳的结果和召回片段再做一次cosine计算,避免出现幻觉。同时,企业还可以利用langchain里面的map_reduce和refine等提高回答的准确性,甚至还可以通过大模型针对数值计算类的提问生成计算函数等。 企业知识库问答构建可以大幅提高企业员工的工作效率,不仅可以摆脱过去查文档的方式的限制,辅助业务智能决策,同时还可以将企业文档进行分领域的归纳管理,充分发挥知识价值,它是企业构建可落地大模型应用的另一重要方向。
企业知识库问答构建可以大幅提高企业员工的工作效率,不仅可以摆脱过去查文档的方式的限制,辅助业务智能决策,同时还可以将企业文档进行分领域的归纳管理,充分发挥知识价值,它是企业构建可落地大模型应用的另一重要方向。
与此同时,基于大模型和启发式AI规划的AI Agent是另一产品应用方向。李飞博士介绍,“它更强调通过大模型生成内容和想法后如何去执行动作。大模型是控制器,Agent是智能体,用于链接所有内容以拓展大模型边界,当基于大模型产生想法和内容之后,企业可通过Agent完整地运转、执行任务。例如,在复杂的企业营销场景下,执行团队只需输入一个目标和对应的营销人群,数势AI Agent便是通过大模型能力进行规划以及任务的拆解,拆解完成后形成动作指令,匹配相应的营销工具,自动完成营销活动设计并生成最终结果。”
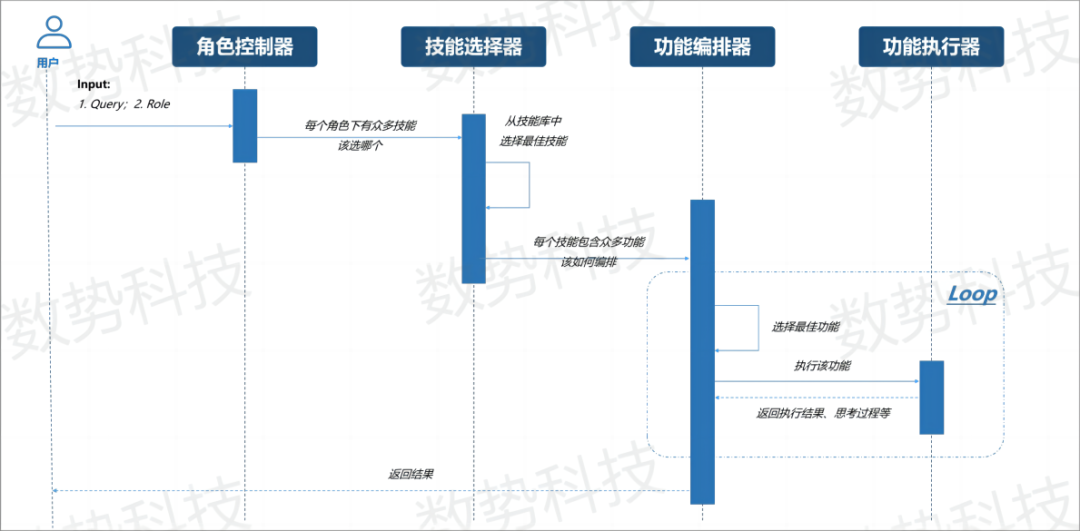
这将赋能企业营销能力,支持企业通过自然语言、数据资产和专家系统,连接企业的员工、系统和流程,让营销应用操作、交互更简单。
END
商务合作:business@digitforce.com
市场合作:marketing@digitforce.com
电话:010-53383810 (工作日10:00-19:00)地址:北京市海淀区花园路庚坊国际大厦15层